
GaussDB(DWS) Core Technologies
GaussDB(DWS) uses a distributed shared-nothing architecture, supports hybrid row-column storage, and is highly available, reliable, secure, and intelligent.
Shared-Nothing Architecture
Each GaussDB(DWS) database instance (Data Node, or DN) has its own CPU, memory, and storage. None of these resources are shared.
The shared-nothing MPP architecture ensures full access to CPU, I/O, and memory resources, and performance improves linearly as the cluster is scaled out, supporting up to petabytes of data.
Distributed Storage
GaussDB(DWS) horizontally shards tables and distributes tuples across nodes based on a configured distribution policy. In a query, you can filter out unnecessary data and quickly find the data you need.
GaussDB(DWS) also partitions table data into non-overlapping ranges.
Partitioning gives you the benefits described in the following table.
Table 2-1 Benefits of partitioning
|
Scenario
|
Benefit
|
|---|---|
Frequently accessed rows are located in only one or a few partitions. |
The search scope is significantly reduced and access performance is improved. |
Most records of a partition need to be queried or updated. |
Performance is significantly improved, because only the specific partitions rather than the entire table are scanned. |
Records that need to be loaded or deleted in batches are located in only one or a few partitions. |
Processing performance is improved because only a few partitions are accessed or deleted. You can avoid scattered operations. |
Data partitioning gives you the following benefits:
- Better manageability
Tables and indexes are divided into smaller and more manageable units. This helps database administrators manage data based on partitions. Maintenance can be performed for specific parts of a table.
- Quicker deletion
Deleting a partition is faster and more efficient than deleting rows.
- Faster query
You can take the following approaches to narrow down the scope of data to be checked or operated on:
-Partition pruning:
Partition pruning or elimination means there are fewer partitions that Coordinator Nodes (CNs) need to scan. This feature greatly improves query performance.
-Partition-wise join:
Partition-wise joins can improve performance if two tables are joined and at least one of them is partitioned on the join key. Partition-wise joins break a large join into smaller joins of "identical" data sets. "Identical" here indicates that the set of partitioning key values on both sides of the join is the same. Only these data sets are used for the join.
Fully Parallel Computing
GaussDB(DWS) uses a set of distributed execution engines to fully utilize the resources and maximize performance.

Figure 2-1 GaussDB(DWS) fully parallel computing
The core technologies of GaussDB(DWS) full parallel computing, shown in the image above, are as follows:
- MPP: node parallelism
The distributed execution framework with VPP user-space TCP protocol enables over 1,000 servers to work in parallel with tens of thousands of CPUs.
- Symmetric multi-processing (SMP): operator parallelism
A SQL statement can be split into many threads running in parallel. Multi-core processors and Non-Uniform Memory Access (NUMA) can be adopted to accelerate the operations.
- Single Instruction Multiple Data (SIMD): instruction parallelism
An x86 or Arm instruction can be performed on data records in batches.
- Low Level Virtual Machine (LLVM) dynamic compilation
You can use LLVM to generate machine code based on key functions, reducing the instructions required for SQL execution to accelerate processing.
Hybrid Row & Column Storage and Vectorized Execution
In GaussDB(DWS), you can use row or column storage for your table, as shown in the following figure.

Figure 2-2 GaussDB(DWS) hybrid row-column storage engine
Column storage allows you to compress old, inactive data to free up space, reducing equipment procurement and O&M costs. GaussDB(DWS) column-store compression supports algorithms such as delta encoding, dictionary compression, RLE, LZ4, and ZLIB, and can automatically select compression algorithms based on your data characteristics. The average compression ratio is 7:1. Compressed data can be accessed without decompression and is transparent to services. This greatly reduces the waiting time for accessing historical data.
The vectorized executor of GaussDB(DWS) can process multiple tuples at a time, greatly improving efficiency. When you query row- and column-store tables at the same time, GaussDB(DWS) can automatically switch between the row- and column-store engines to achieve optimal performance.
Primary/Standby/Secondary High Availability
In a conventional two-copy system, which consists of a primary and a standby server, if one server is faulty, the other will continue to provide services but can keep only one copy of data. If the other server also breaks down, this copy will be permanently lost. You can build a three-copy system to avoid this problem, but it will cost you more in storage. To reduce storage costs, GaussDB(DWS) has a primary/standby/secondary HA mechanism. Even if a server is faulty, there are still two data copies available. This achieves basically the same data reliability as the three-copy mechanism, but with only 2/3 as much storage needed.

Figure 2-3 Primary/Standby/Secondary replication
As shown in this figure, GaussDB(DWS) deploys primary, standby, and secondary servers. When they are running properly, the primary and standby servers perform strong synchronization through log streams and data page streams. The primary server connects to the secondary server but does not send logs or data to it, so the secondary does not use up storage resources. If the standby server breaks down, the primary server will send to the secondary server any logs and data that have not been synchronized. The primary server then starts strong synchronization to the secondary. This switchover is performed in kernels and does not affect transactions. No errors or inconsistency issues will occur.
If the primary server breaks down, the Cluster Manager component promotes the standby server to primary. The new primary server will start strong synchronization to the secondary server. In this way, if one of the Data Nodes (DNs) in a DN group breaks down, two data copies will still be available and to ensure data reliability.
Online Scale-out
A GaussDB(DWS) cluster can have up to 2,048 nodes. Its storage and computing capacities can be improved linearly by adding nodes.
The Node Group technology of GaussDB(DWS) enables the scale-out of multiple tables in parallel, with a speed up to 400 GB per hour on each new node. The following figure shows the scale-out process.
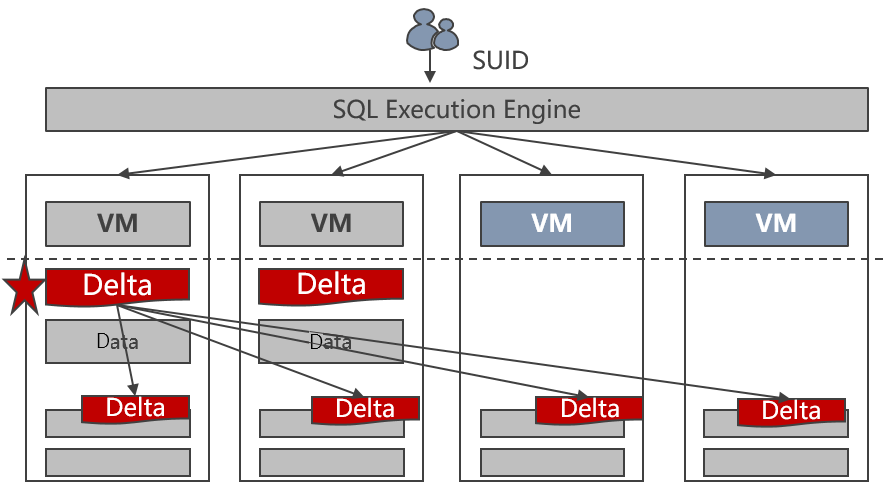
Figure 2-4 Scale-out process
GaussDB(DWS) scale-out has the following advantages:
- Service continuity
Data import and queries are not interrupted during scale-out.
- Consistent hashing and multi-table parallel scale-out
Consistent hashing minimizes the amount of data to be migrated during redistribution.
Multiple tables can be redistributed in parallel. You can specify the redistribution sequence.
You can check the scale-out progress.
- Linear performance increase
GaussDB(DWS) has a fully parallel distributed architecture. The data loading performance, service processing performance, and storage of a cluster linearly increases as nodes are added.
Transparent Security
GaussDB(DWS) supports transparent data encryption (TDE). User experience is not affected by encryption or decryption. Each cluster has a cluster encryption key (CEK). Each database is encrypted using an independent database encryption key (DEK). A DEK is encrypted using a CEK to enhance security. You can use Kerberos to apply for, encrypt, and decrypt keys, and configure encryption algorithms through configuration items in a unified manner. Currently AES and SM4 algorithms are supported. The SM4 algorithm supports hardware acceleration in chips of Hi1620 and later versions.
We help you extract value with big data analytics and protect privacy at the same time. You can define policies to mask certain columns and protect sensitive data. After a data masking policy takes effect, only the administrator and the table owner can access the original data. Masking does not affect data processing. Masked data can still be used for computing. The data will just be masked when the database returns results.
The following figure shows an example. The salary, email address, and mobile phone number of employees are sensitive data. Such data is converted to x marks to protect privacy.

Figure 2-5 Data masking results
The key technologies used for data masking are as follows:
- User-defined scope
You can run DDL statements to apply data masking policies to specific columns.
- User-defined policies
You can customize data masking functions based on built-in numeric, character, and time type masking functions.
- Access control
After data is masked, only the administrator and the table owner can see the data.
- Data availability
Masked data can be used for computing, but will be masked when the database returns results.
SQL Self-Diagnosis
Conventional SQL performance tuning, especially in distributed databases is complicated and difficult. Effective troubleshooting requires extensive professional skills and experience. GaussDB(DWS) intelligently analyzes performance issues during SQL execution, recording and presenting the issues in a way that is easy to understand. You can easily learn how you should optimize your SQL statements to improve performance.
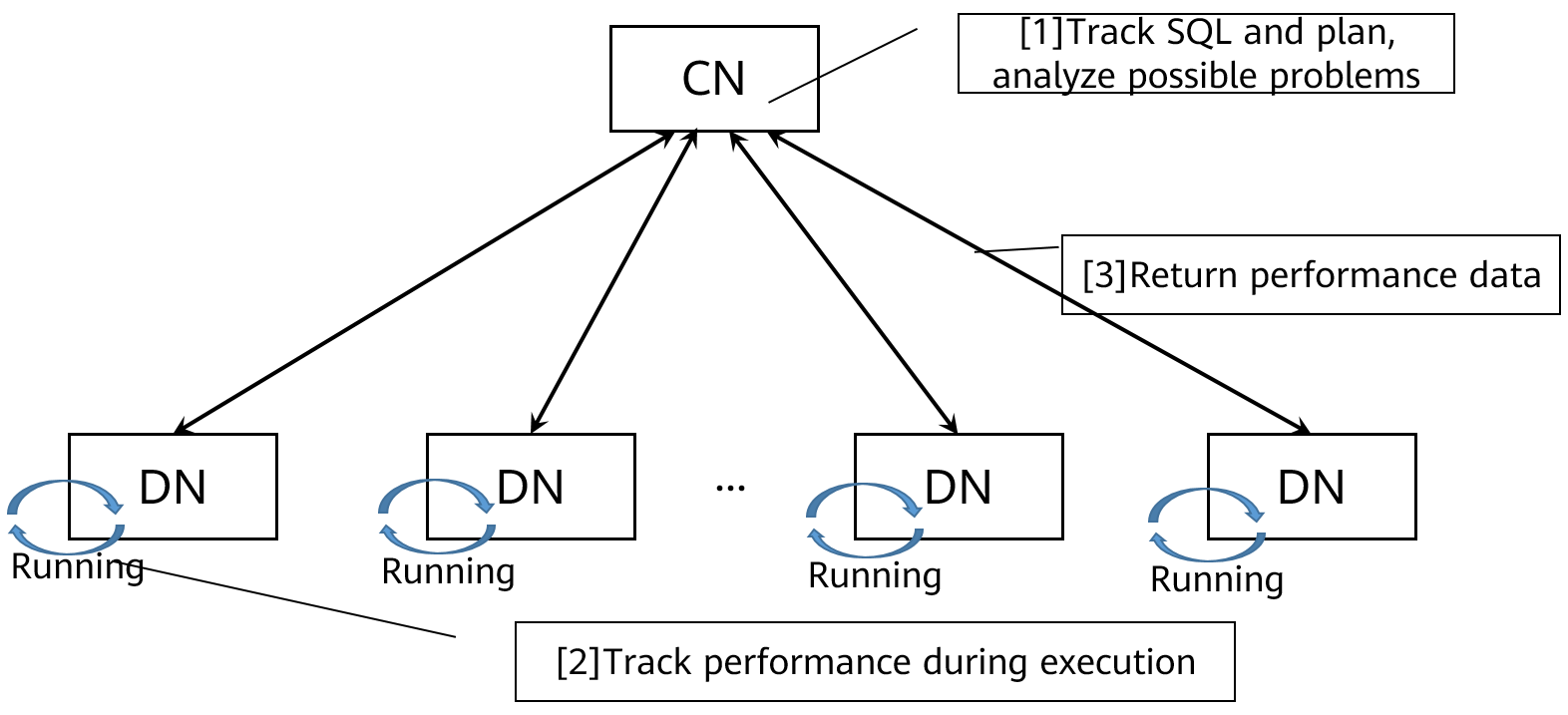
Figure 2-6 How SQL self-diagnosis works