

云搜索服务 CSS-优化Elasticsearch和OpenSearch集群写入性能:数据写入流程
时间:2025-02-18 16:36:44
 下载云搜索服务 CSS用户手册完整版
下载云搜索服务 CSS用户手册完整版
复制链接到剪贴板
分享文章到微博
分享文章到朋友圈
数据写入流程
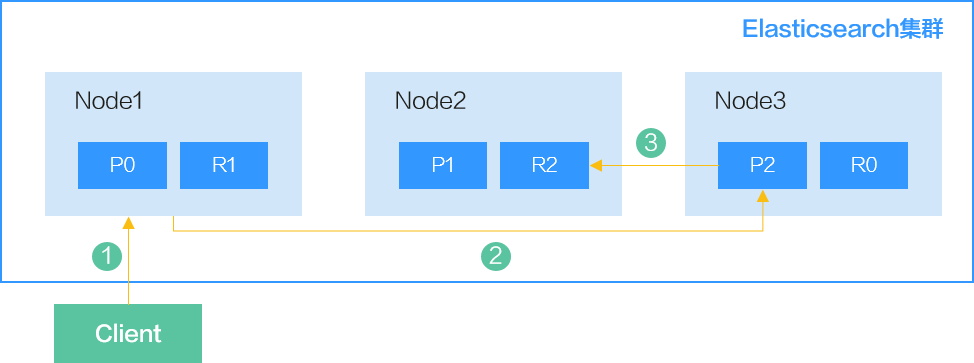
如图1所示,以Elasticsearch集群为例,介绍客户端往Elasticsearch或OpenSearch集群中写入数据的流程。图中的P表示主分片Primary,R表示副本分片Replica,主副分片在数据节点Node里是随机分配的,但是不能在同一个节点里。
- 客户端向Node1发送写数据请求,此时Node1为协调节点。
- 节点Node1根据数据的_id将数据路由到分片2,此时请求会被转发到Node3,并执行写操作。
- 当主分片写入成功后,它将请求转发到Node2的副本分片上。当副本写入成功后,Node3将向协调节点报告写入成功,协调节点向客户端报告写入成功。
Elasticsearch中的单个索引由一个或多个分片(shard)组成,每个分片包含多个段(Segment),每一个Segment都是一个倒排索引。
图2 Elasticsearch的索引组成

如图3所示,将文档插入Elasticsearch时,文档首先会被写入缓冲区Buffer中,同时写入日志Translog中,然后在刷新时定期从该缓冲区刷新文档到Segment中。刷新频率由refresh_interval参数控制,默认每1秒刷新一次。更多写入性能相关的介绍请参见Elasticsearch的官方介绍Near Real-Time Search。

support.huaweicloud.com/bestpractice-css/css_07_0018.html






