
Introducción a GaussDB(for MySQL)
29 sep. 2021GaussDB(for MySQL): liberando el poder de la integración vertical de la pila de la nube
El cómputo en la nube está experimentando una popularidad creciente, y uno de los componentes claves de la pila de la nube son los servicios de bases de datos transaccionales. Las aplicaciones dependen de servicios de bases de datos escalables de alto rendimiento y gestionados para beneficiarse plenamente de la plataforma de la nube. Y las bases de datos en la nube necesitan utilizar eficientemente la infraestructura subyacente de la nube para alcanzar el potencial de las operaciones en la escala de la nube.
GaussDB(for MySQL) es una base de datos nativa de la nube basada en MySQL, disponible como un servicio totalmente gestionado en HUAWEI CLOUD, que está dirigida tanto a clientes de Internet como empresariales. En este artículo, les hablaré sobre las cargas de trabajo comunes de los clientes y cómo aprovechamos las capacidades únicas de la pila de cómputo de HUAWEI CLOUD para procesar dichas cargas de trabajo.
Quiénes son los clientes en la nube y cuáles son sus cargas de trabajo
La percepción, particularmente en China, es que solo las startups de Internet adoptan la plataforma de la nube, y que MySQL es popular como base de datos en la nube debido a su popularidad entre las compañías de Internet. Pero en realidad, las empresas comenzaron a adoptar el concepto de nube desde hace años, y esta también es la tendencia actual en China. MySQL, como la base de datos de código abierto más popular del mundo, ha sido ampliamente adoptada en todas las industrias, así como en las compañías de Internet.
Entonces, ¿cuál es la carga de trabajo típica de los clientes de bases de datos en la nube? Estas son las dos características que observamos: la primera, un volumen de datos cada vez más grande: una cantidad de uno o dos dígitos de terabytes de datos inicial, que crece con el tiempo; y la segunda, una mezcla de operaciones insert/delete/update/point de consultas de análisis selectas y complejas. Además, hay operaciones de DDL ocasionales.
El reto es cómo hacer que la base de datos se desempeñe adecuadamente cuando el volumen de datos es grande. Los clientes desean ejecutar consultas de análisis y mantener el throughput de la carga de trabajo transaccional principal. Las consultas son complejas debido a la naturaleza de la lógica de negocio de las empresas. Afortunadamente, en MySQL 8.0 se agregó la compatibilidad tan esperada de SQL con funciones de ventana y CTE recursivos. Para los datos no estructurados, la compatibilidad de MySQL con JSON ya es extremadamente popular.
Descripción de la arquitectura de GaussDB(for MySQL)
Desde una perspectiva general, GaussDB(for MySQL) es similar a AWS Aurora. Está construido sobre la base de un sistema de almacenamiento distribuido compartido, y el volumen máximo para una base de datos es actualmente 128 TB. Se utilizan un nodo principal para la carga de lectura y escritura, y hasta quince réplicas de solo lectura para la carga de lectura. El motor SQL es un servidor MySQL versión 8.0 ampliamente modificado y, por lo tanto, 100 % compatible con MySQL tanto en términos de sintaxis como de semántica. Hay una red RDMA entre los nodos de cómputo y de almacenamiento.
El sistema de almacenamiento utilizado por el servicio GaussDB(for MySQL) es un almacenamiento en la nube, en diferentes AZ y altamente confiable. En la nube pública, los sistemas de almacenamiento pueden contener un gran clúster con cientos de nodos. Su escalamiento en términos de nodos de almacenamiento puede alcanzar niveles mayores que los que se encuentran en soluciones locales de un solo tenant. Los nodos SQL envían los registros REDO al almacenamiento y las páginas se materializan en la capa de almacenamiento; este diseño reduce significativamente la comunicación de red para las cargas de trabajo con actualización intensiva. Las páginas pertenecientes a una sola base de datos se organizan en segmentos, y los segmentos se distribuyen entre múltiples nodos de almacenamiento.
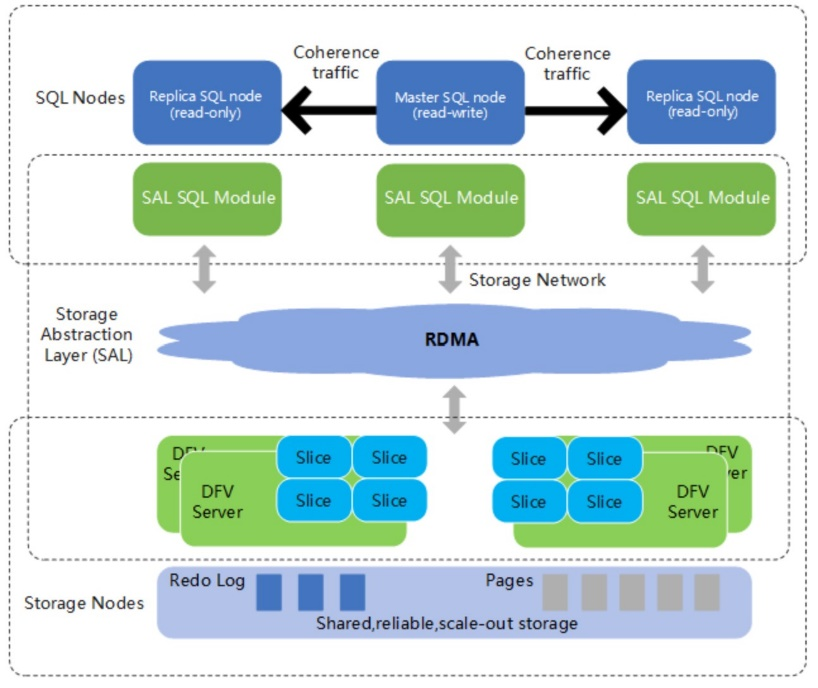
Arquitectura de GaussDB(for MySQL)
Fortaleza única de Huawei: integración vertical
Las bases de datos en la nube, a diferencia de las bases de datos tradicionales locales, permiten la integración vertical de todas las capas en la pila de la nube. Huawei, como proveedor líder en todas las capas, está en una posición única para convertirse en uno de los líderes de la industrial de la nube.
Lo más cercano a las bases de datos en la pila de la nube es el almacenamiento. Las bases de datos locales de tipo “solo software” necesitan trabajar con almacenamiento general a través de interfaces estándares de sistemas de archivos, lo que deja poco espacio para la optimización. Oracle Exadata, por otro lado, ya demostró el poder de la integración entre el almacenamiento y la base de datos en la forma de un dispositivo.
En la nube, esta integración juega un papel aún mayor, ya que el almacenamiento en la nube tiene una escalabilidad mucho mayor que la que se logra con Oracle Exadata, y permite a los clientes escalar dinámicamente el sistema según el volumen de datos y la carga. Dado que el almacenamiento se comparte entre muchos tenants, y que no todos ellos estarán ejecutando análisis de gran escala todo el tiempo, podemos lograr una tasa de utilización de los recursos mucho mayor mediante la descarga de partes del procesamiento de consulta a la capa de almacenamiento.
Mejora del rendimiento a través de la paralelización
Un enfoque genérico para mejorar el rendimiento es a través de la paralelización, la cual puede hacerse en múltiples capas. La versión comunitaria de MySQL 8.0 solo admite la ejecución de consultas con un solo subproceso y no puede aprovechar completamente todos los núcleos disponibles en el hardware para consultas complejas. Hemos modificado el motor de ejecución de MySQL, para permitir que una sola consulta se ejecute usando múltiples subprocesos en paralelo. La infraestructura en la nube, a diferencia de las soluciones locales, nos permite utilizar el escalamiento vertical en el nodo de cómputo. La variante de VM más grande actualmente tiene 64 núcleos, lo que da una idea del nivel de paralelización máximo que podemos lograr mediante la ejecución de consultas en paralelo. Esta optimización es más adecuada cuando los datos caben en su mayoría en el grupo de búferes. Explicaremos este aspecto con detalle en otro artículo.
La carga de trabajo del cliente no solo contiene DML, también contiene DDL como la creación de índices o el cambio de tipo de datos de una columna. Aunque la mayoría de los DDL están disponibles en MySQL, algunas operaciones pueden estar bloqueadas, y este problema se hace más grande con el uso de la replicación lógica. GaussDB evita este problema gracias a que utiliza la replicación física. Cuando una tabla es grande, las operaciones DDL pueden tardar muchas horas en completarse. Para admitir el volumen de datos que comúnmente vemos en la nube, la necesidad de optimizar los DDL es obvia. Hemos encontrado una forma innovadora para procesar el DDL, y esta innovación también la exploraremos en un artículo posterior.
Otra capa que permite un grado aún mayor de paralelización es el almacenamiento, ya que el sistema de almacenamiento puede tener potencialmente cientos de nodos y miles de núcleos. Este sistema de almacenamiento masivo en la escala de la nube utilizado en GaussDB(for MySQL) es uno de los componentes claves que aprovechamos para mejorar el rendimiento de consulta. Combinado con la ejecución de consultas en paralelo, podemos lograr mejoras en el rendimiento de consultas de más de 100 veces.
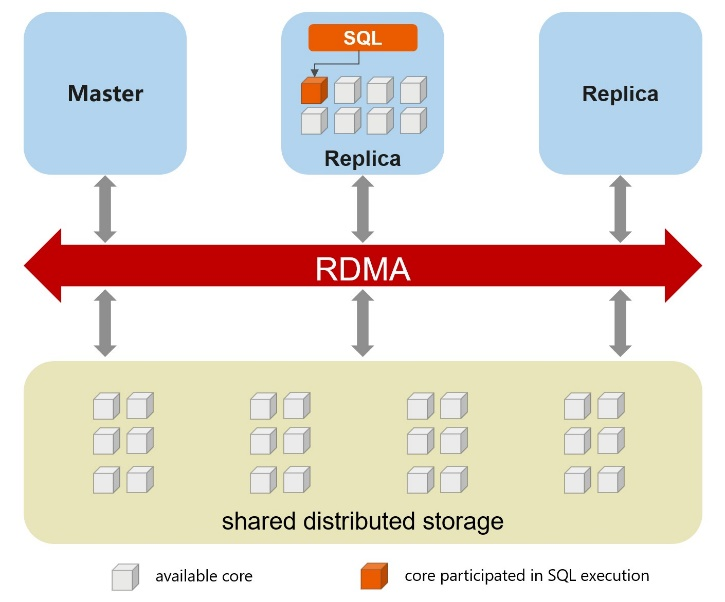
Ejecución de consultas con un solo subproceso en la capa de cómputo
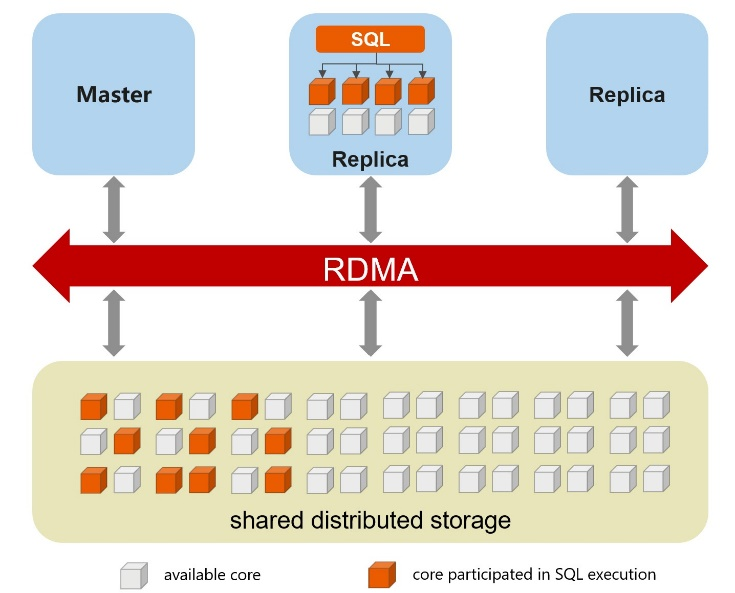
Procesamiento paralelo en las capas de cómputo y almacenamiento
Aprovechando el almacenamiento en la nube para procesar consultas (NDP)
En GaussDB(for MySQL) los datos se organizan en segmentos y se distribuyen a través de múltiples nodos de almacenamiento. Aprovechamos esta distribución de datos y los recursos de cómputo disponibles para realizar el procesamiento de consultas donde se encuentren los datos, sin transferirlos a los nodos de cómputo. En la terminología de bases de datos, lo llamamos procesamiento cerca de los datos (NDP: near data processing) o transferencia de consultas a capas inferiores (query push down). Básicamente, transferimos partes del procesamiento de consultas al sistema de almacenamiento distribuido cercano a los datos. Las operaciones que mandamos a niveles inferiores son operaciones intensivas de datos, como el análisis de tablas y de índices. La proyección y la evaluación de algunas condiciones WHERE, así como las agregaciones se ejecutan en la capa de almacenamiento, de modo que solo se devuelven al servidor las filas y las columnas coincidentes necesarias para una consulta en particular en lugar de páginas completas. Además de la paralelización, este enfoque también reduce el volumen de E/S de la red, ya que el volumen de datos transferido a los nodos de cómputo disminuye significativamente. Además, NDP también permite la utilización completa del ancho de banda local para las cachés y los medios de almacenamiento.
La transferencia de carga al almacenamiento funciona mejor cuando una consulta necesita analizar una gran cantidad de datos y los datos todavía no están en el grupo de búferes de InnoDB. Como ejemplo, el siguiente gráfico muestra que NDP y la ejecución de consultas en paralelo mejoran el tiempo de ejecución de TCP-H Q12 en una cantidad impresionante de 34 veces. Un artículo específico sobre NDP explorará con más profundidad los detalles técnicos y proporcionará un análisis completo del rendimiento.
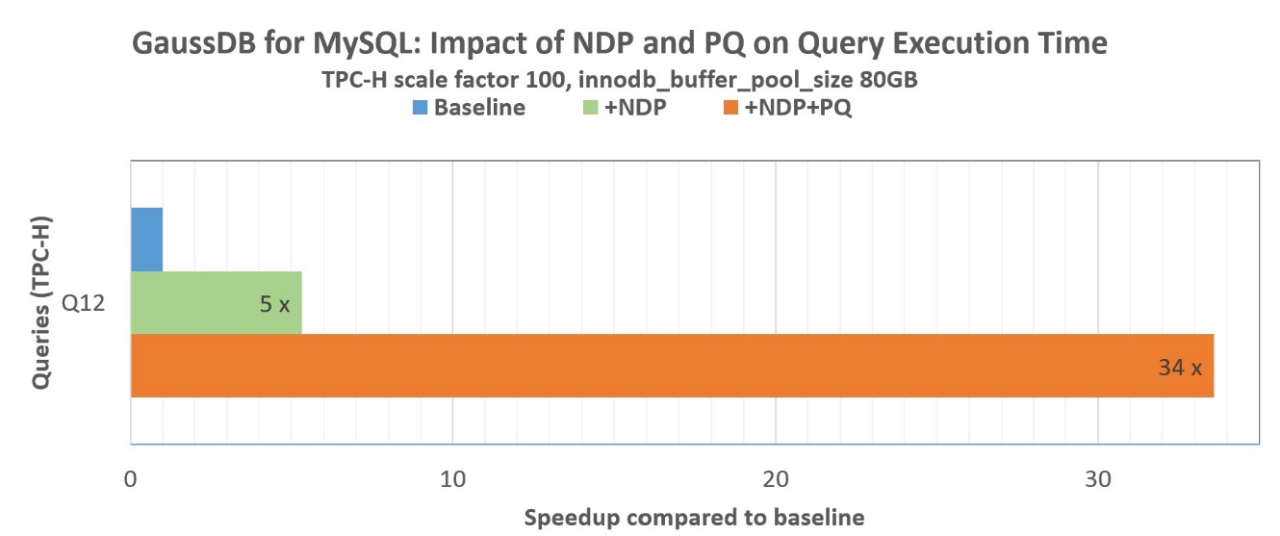
Aceleración comparada con el valor de referencia
Dirección futura
GaussDB(for MySQL) está diseñado como una base de datos nativa de la nube, y la arquitectura de la nube soporta un marco de trabajo extremadamente potente y flexible para la integración vertical. Los recursos de cómputo y almacenamiento están desacoplados y se escalan independientemente, pero aun así están estrechamente integrados en términos de funcionalidad, y las operaciones de bases de datos pueden ejecutarse en múltiples capas. En el futuro, las operaciones de bases de datos también podrán transferirse a las tarjetas de red y a otros componentes en la nube, en vez de limitarse a los nodos de cómputo y almacenamiento.
Creemos que la profunda integración de la pila de cómputo de la nube es la clave para liberar el poder de las bases de datos en la nube, y Huawei está en una posición única para lograrlo, como se demostró aquí con GaussDB(for MySQL).
Esté al pendiente, tendremos más noticias pronto.