

随着生成式 AI 技术的飞速发展,大语言模型(LLM)正逐步走入生产系统、产业服务与日常应用中。如何支撑这些超大模型在云端的高效、稳定、低成本运行,成为业界与学界关注的焦点。近日,在三大国际顶级会议——USENIX ATC 2025、ICML 2025 和 ACL 2025中,华为云存储创新LAB与北京大学、南京大学等单位合作的三篇论文成功入选,全面展示了从整体系统架构、prefill阶段加速到decode阶段加速三位一体的技术突破,为构建下一代大模型推理基础设施奠定了坚实地基。
【DEEPSERVE——构建大模型推理的云原生“地基引擎”(ATC 2025)】
在系统与云计算顶会 ATC 2025 上,论文《DEEPSERVE: Serverless Large Language Model Serving at Scale》系统性地提出并落地了一个支持 大规模并发、Serverless 弹性、Ascend NPU 原生优化 的云平台 DEEPSERVE,支撑了华为云大语言模型服务的核心工作负载。
三大挑战
随着 AI 服务形态从静态模型查询扩展到微调、Agent 执行、长对话、RAG 等动态任务,云平台面临三大挑战:
- ● 工作负载极度多样: 短至几秒(推理),长至数小时(训练),难以高效调度。
- ● 推理请求高度状态化: KV 缓存等中间状态需在多节点间同步传递。
- ● 请求量起伏剧烈: 系统需具备毫秒级响应与秒级扩容能力。
四大技术支柱
为此,DEEPSERVE 提出并实现如下关键设计:
- ● Serverless 抽象: 构建“请求–作业–任务”三级架构,动态调度、自动伸缩。
- ● 高性能推理引擎 FLOWSERVE: 基于微内核 + SPMD 并行执行框架,原生适配 Ascend NPU。
- ● 多形态调度算法: 支持 PD-disaggregated 与 PD-colocated 部署,结合负载感知与缓存复用策略。
- ● 极速弹性优化: 引入 Pod 预热、模型预加载、NPU-Fork 等优化,秒级扩展至 64 实例。
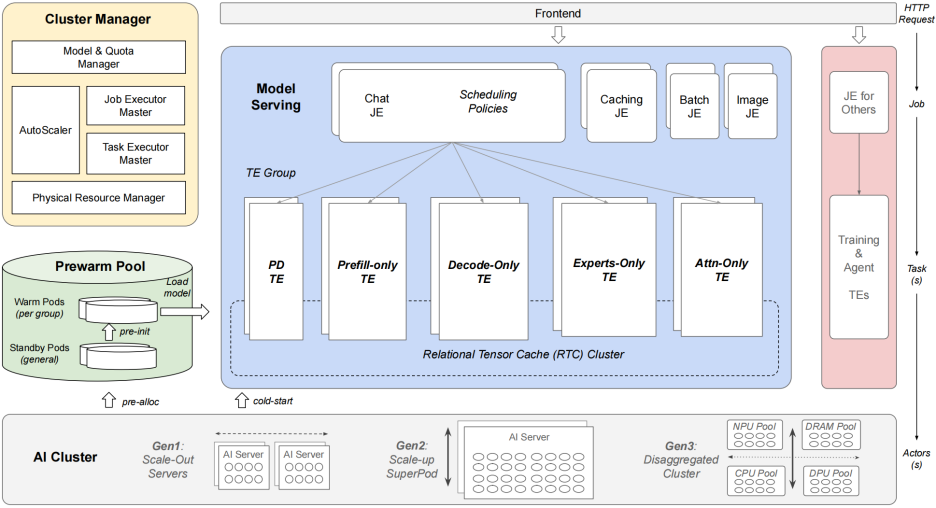
▲ DEEPSERVE 的 Serverless 架构与核心模块概览
DEEPSERVE 已在 Ascend NPU 超大集群(910B集群或CLOUDMATRIX384 SuperPod)中正式部署并稳定运行一年以上,为华为云生成式AI提供稳定支撑。
【EPIC——解锁“上下文重用”的效率极限(ICML 2025)】
在机器学习顶会 ICML 2025 上,论文《EPIC: Efficient Position-Independent Caching for Serving Large Language Models》进一步在 DEEPSERVE 之上提出了 位置无关缓存(PIC)机制,有效突破传统上下文缓存只能重用“前缀”部分的限制,显著提升推理吞吐。
传统缓存的局限
目前主流的上下文缓存策略,如在 vLLM 等系统中广泛应用的“前缀缓存”,仅在用户输入的开头完全相同时可复用计算结果,在 Few-Shot 学习或 RAG 等场景中复用率极低。
LegoLink:兼顾速度与精度的关键算法
EPIC 所提出的 LegoLink 算法基于以下两大洞察:
- ● 注意力黑洞”现象: 每段文档开头的 token 吸收了大量注意力,抑制其他 token 获取有效上下文。
- ● 静态稀疏重计算策略:精选每段开头极少数 token 进行重算,修复上述偏差。
实验显示,EPIC 在多个真实推理场景中实现:
- ● 单请求延迟最高降低 3×,吞吐提升高达 8×;
- ● 保持精度损失不超过 7%;
- ● 可与 vLLM 等主流框架兼容集成。
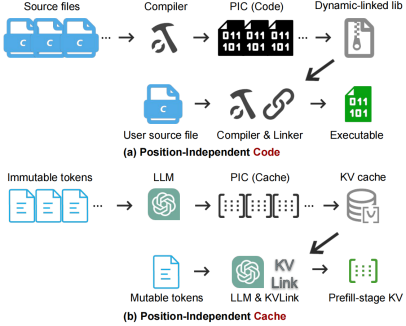
▲ 什么是PIC
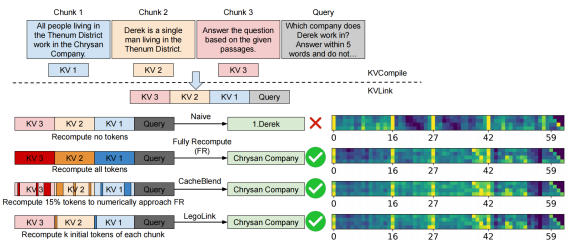
▲ EPIC 系统的核心创新 LegoLink 算法示意图
【RaaS——破解长推理的“不可能三角”(ACL 2025)】
在自然语言处理顶会 ACL 2025 上,论文《RaaS: Reasoning-Aware Attention Sparsity for Efficient LLM Reasoning》聚焦推理阶段中 KV 缓存爆炸式增长的性能瓶颈,首次实现 同时具备高准确率、低时间复杂度与低内存占用 的 Attention Sparsity 算法,打破了行业长期存在的“不可能三角”困境。
推理阶段的瓶颈
长推理任务(如数学推理、程序生成)在解码阶段需逐 token 构造 KV 缓存,造成时间与内存双重指数增长:
- ● 生成 10K tokens 的推理请求,其解码阶段占据了 99% 的执行时间;
- ● 当前最优算法 Quest 虽能降低时间复杂度至 O(L),但仍需 O(N) 的内存空间。
RaaS 针对性设计出两条稀疏策略:
- ● 基于时间戳的 LRU 缓存策略,管理 milestone 生命周期;
- ● 完整保留 prefill token 的 KV 向量,保证 phoenix 能“重生”。
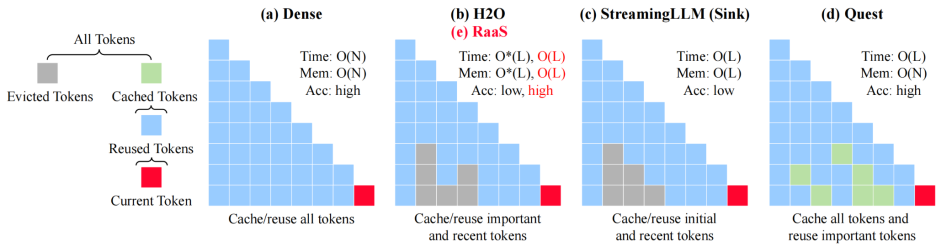
▲ RaaS 算法在准确率、延迟和内存之间取得最佳平衡
实验表明,RaaS 与 Quest 精度、延迟相当,但将内存复杂度从 O(N) 降至 O(L),显著减少显存占用,适配大规模部署。
【打造从“基础设施”到“核心加速”的大模型推理技术栈】
从 DEEPSERVE 提供的可扩展、Serverless 云原生平台,到 EPIC 优化上下文缓存重用,再到 RaaS 在解码阶段以最小代价保留关键推理token,三项工作共同构建出一个高吞吐、低延迟、强鲁棒的大模型推理体系,覆盖了推理全过程的系统瓶颈与算法难题。
这三项论文分别入选 ATC、ICML、ACL 三大顶会,体现了中国团队在大模型推理系统与算法优化领域的持续深耕与国际影响力。华为云也将继续推动相关技术的产业化与开源化,助力全球开发者高效构建智能应用。