









基于您的业务场景为您推荐模型
基于您的业务场景为您推荐模型MB



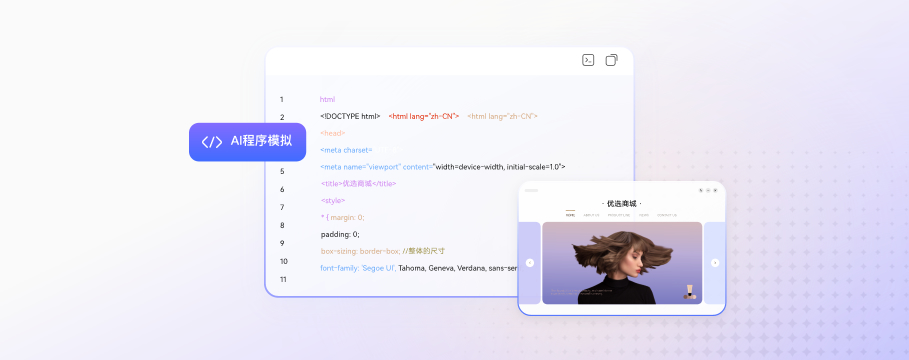
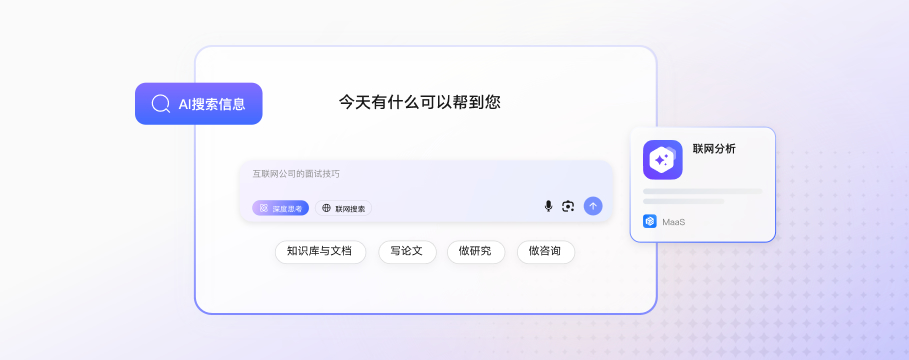

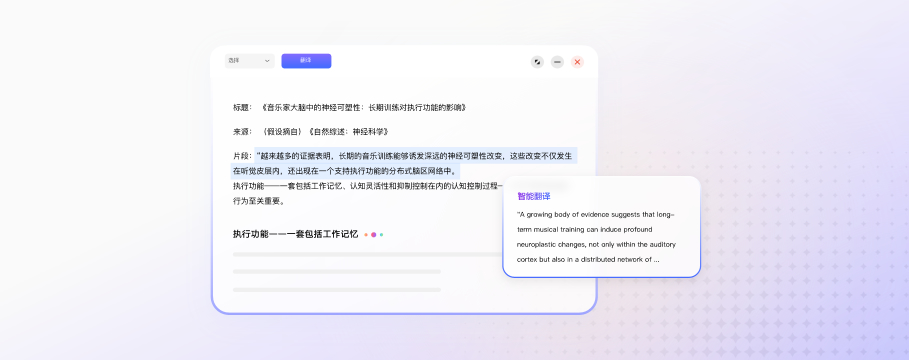
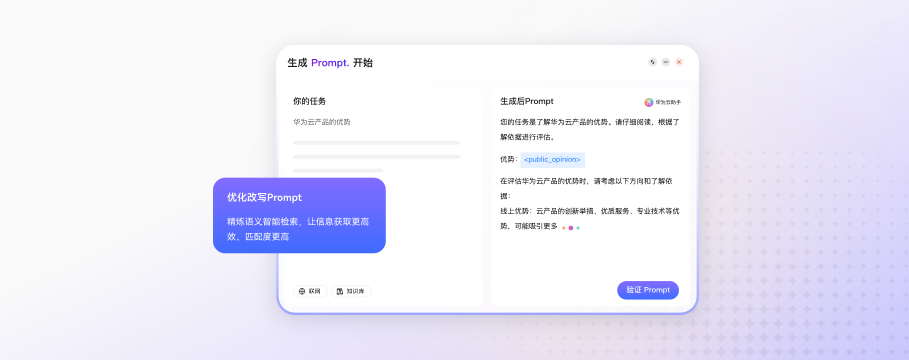
一图了解华为云MaaS
一图了解华为云MaaS



端到端加密,全链路安心
在MaaS中导入模型时,支持用户选择HTTPS传输协议,为保证数据传输的安全性,推荐用户使用更加安全的HTTPS协议。
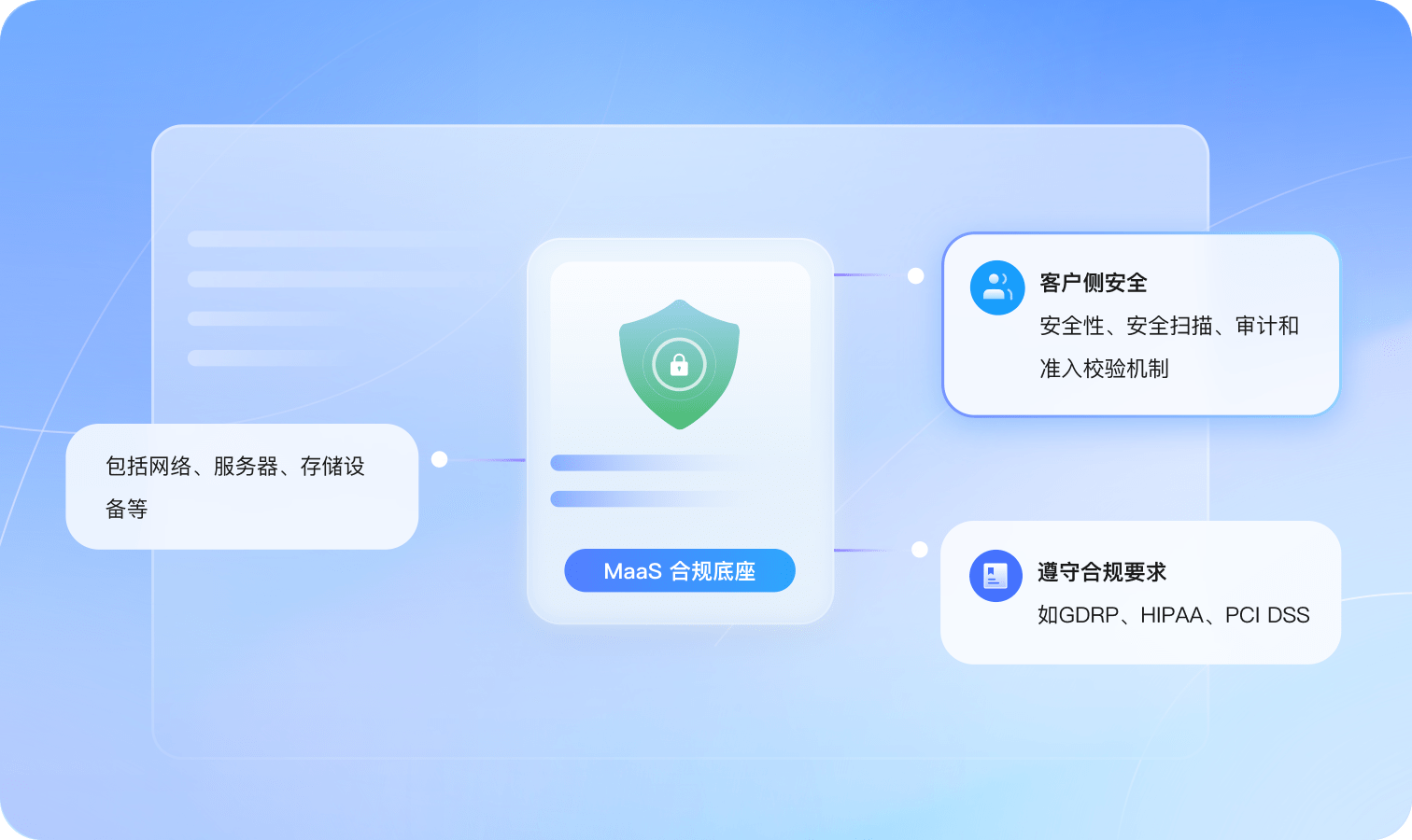
操作全程可审计,风险全周期可控
提供对各种云资源操作记录的收集、存储和查询功能,可用于支撑安全分析、合规审计、资源跟踪和问题定位等常见应用场景。
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
在MaaS中导入模型时,支持用户选择HTTPS传输协议,为保证数据传输的安全性,推荐用户使用更加安全的HTTPS协议。
提供对各种云资源操作记录的收集、存储和查询功能,可用于支撑安全分析、合规审计、资源跟踪和问题定位等常见应用场景。






