

Ray支持分布式训练和调优,可以用于处理大规模数据集和模型,使得模型训练更加高效 大模型 使用大模型实现智能对话、自动摘要、机器翻译、文本分类、图像生成等任务 实时湖仓 提供标准SQL接口,用户仅需使用SQL便可实现海量数据分析 数据工程 高效处理大规模数据,通过并行计算加速数据处理过程,如数据清洗、转换和聚合
盘古大模型 盘古大模型 大模型开发平台ModelArts Studio 大模型开发平台ModelArts Studio 支持百模千态的大模型工具链平台,构建规模化可复制的行业大模型解决方案,深入行业解决行业难题 支持百模千态的大模型工具链平台,构建规模化可复制的行业大模型解决方案,深入行业解决行业难题
数据库安全服务 DBSS 数据库安全服务 DBSS 数据库安全服务 DBSS 资源 数据库安全服务 DBSS 资源 提供数据库审计,SQL注入攻击检测,风险操作识别等功能,保障云上数据库的安全 提供数据库审计,SQL注入攻击检测,风险操作识别等功能,保障云上数据库的安全 购买 智能客服
控制台 文档 数据库学习路径 数据库学习路径 数据库理论基础 1、数据库介绍 2、数据库基础知识 3、SQL语法入门 4、SQL语法分类 华为云数据库介绍与实战 1、数据库入门与应用 2、数据库进阶学习 3、7天玩转MySQL基础实战营 云数据库方案设计与调优 1、云享读书会《SQL优化核心思想》
2022 2022-03-22 华为云盘古大模型荣获深圳人工智能科技进步奖 华为云盘古NLP大模型是业界首个千亿参数规模的中文大模型,中文理解能力接近人类水平。盘古CV大模型的小样本学习能力表现优异,在ImageNet 1%、10%数据集上的小样本分类精度上均达到目前业界最高水平(SOTA)。
空闲期 搭配使用 数据接入服务 DIS 云数据库 RDS for MySQL 大企业 日志分析 大企业的部门比较多,不同部门在使用云服务时,需要对不同部门的员工的权限进行管理,包括计算资源的创建、删除、使用、隔离等。同时,也需要对不同部门的数据进行管理,包括数据的隔离、共享等 优势
盘古预测大模型 盘古预测大模型 通过历史数据学习得到的面向结构化任务场景,针对事物发展趋势、状态类别等进行量化预测的预训练大模型 通过历史数据学习得到的面向结构化任务场景,针对事物发展趋势、状态类别等进行量化预测 重磅发布盘古统一编码预测大模型 跨模态知识融合 专家咨询 ModelArts
了解API的描述、语法、参数说明及样例等内容 SDK 了解如何获取、安装和调用华为云SDK EVS云小课 带您快速了解并学习购买共享云硬盘 云硬盘论坛 行业资讯、干货分享等一系列内容 博客 汇聚精品内容,云集技术大咖 增值服务 增值服务 支持计划 7*24小时全产品技术支持 专业服务 提供上云、用云、管云全生命周期服务
获取海量开发者技术资源、工具 开发者计划 使能开发者基于开放能力进行技术创新 开发支持 专业高效的开发者在线技术支持服务 开发者学堂 云上学习、实验、认证的知识服务中心 开发者活动 开发者实训、热门活动专区 社区论坛 专家技术布道、开发者交流分享的平台 文档下载 NAT网关 NAT文档下载
使用云框架的两个常见原因: 在表格中安排数据,从而用来呈现数据间的关系;或者在ap上组织图形和文本,也就是用于app布局。1.增大系统容量。我们的业务量越来越大,而要能应对越来越大的业务量,普通框架的性能已经无法满足了,我们需要专业的框架才能应对大规模的应用场景。所以,我们需要垂
等AI建模服务。(4)提供多级数据聚合与治理服务、贸易主题指标数据统计分析服务、物流客户价值分析服务、物流客户服务质量分析服务、经营收入&作业量关联分析服务、作业量&成本&效率关联分析服务、生产作业资源合理性分析服务等数据集成服务。3、应用使能框架现场服务,包括:方案咨询规划服务
)通过在线学习文章视频、每日一测可获取系统积分奖励,系统提供员工的学习积分报表,各单位可根据报表情况进行奖惩,以考核来促进学习。 后台管理功能: (1)资料库作为员工学习培训数据支撑基础,包含法律法规、行业标准、规范、规程、规章制度、操作手册、案例等海量学习资料,资料
数据库特性:系统支持多数据库连接和动态切换机制,支持分布式数据库。犹如企业开发的一把利刃,跨数据库应用和分布式支持从此无忧。ThinkPHP是一个快速、简单的基于MVC和面向对象的轻量级PHP开发框架。
不再需要F5等负载均衡硬件·运维管理统一RPC调用框架,技术对齐,系统SOA化,满足业务的快速变化需求·开发人员提升开发效率、保证服务质量服务变化主动通知应用,实现应用、服务的横向扩展,服务总线上可监控服务压力,调节负载能力,数据、缓存均可以横向扩展,对服务端来说是透明的,通过服务总线注册、监控、发现应用或服务
深度学习计算服务平台是中科弘云面向有定制化AI需求的行业用户,推出的AI开发平台,提供从样本标注、模型训练、模型部署的一站式AI开发能力,帮助用户快速训练和部署模型,管理全周期AI工作流。平台为开发者设计了众多可帮助降低开发成本的开发工具与框架,例如AI数据集、AI模型与算力等。
天冕联邦学习平台是天冕利用前沿信息技术打造的高效安全数据合作解决方案,在充分保护各方用户数据安全、非共享数据情况下打破数据孤岛,实现跨数据、跨行业的合作。 天冕联邦学习平台,联邦建模,联合建模,隐私计算,多方安全计算
块、论坛模块、测验模块、资源模块、问卷调查模块、互动评价(workshop)。Moodle具有先进的教学理念,创设的虚拟学习环境中有三个维度:技术管理维度、学习任务维度和社会交往维度,以社会建构主义教学法为其设计的理论基础,它提倡师生或学生彼此间共同思考,合作解决问题。组件Moodle
轻学堂企业学习平台是喜马拉雅旗下专注企业培训和员工成长的品牌,成立于2017年,通过内容、工具、运营三位一体,搭建数字化学习内容平台,助力企业人才成长。严选企业需要员工发展、职业素养提升、专业技能、管理能力等精品书课内容。附:产品区别说明有声书+精品课,内容更丰富、上新更快,赠送学习平台全套工具,无限量上传空间
个 物联网设备接入平台_mqtt设备接入_Iot设备接入验证 主机安全扫描报告_主机安全检测报告_主机安全报告 免费数据库GaussDB NoSQL_云数据库_数据库免费吗 查看更多 收起 服务咨询 华为云商店为isv和咨询合作伙伴提供了一个新的销售渠道,以向华为客户销售解决方案。
为什么他们选择了GaussDB “星河”数据库标杆案例!工商银行&华为云GaussDB再创佳绩 全球银行最大分布式核心系统全面上线,邮储银行做到了! 案例集锦|科技赋能,华为云GaussDB助千行百业数字化转型 实时支撑千亿数据,高效出行的背后全因有TA 梦幻联动! 金蝶&华为云面向大企业发布数据库联合解决方案
实时支撑千亿数据,高效出行的背后全因有TA 梦幻联动! 金蝶&华为云面向大企业发布数据库联合解决方案 权威认证 中国首个!华为云GaussDB数据库荣获国际CC EAL4+级别认证 再获认可!华为云GaussDB数据库荣获年度优秀创新软件产品大奖 重磅发布!西骏数据与华为云GaussDB完成兼容互认证
分必要。本课程主要介绍如何搭建一个可视化大屏,为企业提供精准、高效的支持。 基于流计算的可视化大屏,为企业、政府带来全新的视觉体验 适合人群:面向对实时流计算和可视化感兴趣的从业人员,社会大众和高校师生 培训方案:结合华为云服务搭建基于流计算的可视化平台 技术能力:了解流计算的关
分必要。本课程主要介绍如何搭建一个可视化大屏,为企业提供精准、高效的支持。 基于流计算的可视化大屏,为企业、政府带来全新的视觉体验 适合人群:面向对实时流计算和可视化感兴趣的从业人员,社会大众和高校师生 培训方案:结合华为云服务搭建基于流计算的可视化平台 技术能力:了解流计算的关
我们专注于五大行业(汽车零配件、光伏、光电缆、医疗设备、电子),深耕行业化需求,为客户提供专业的解决方案和产品。 我们专注于五大行业(汽车零配件、光伏、光电缆、医疗设备、电子),深耕行业化需求,为客户提供专业的解决方案和产品。 欧软云MES 当地化服务 我们在全国七大战区设立20
数据可视化 数据可视化 数据可视化服务(Data Lake Visualization)是一站式数据可视化平台,适配云上云下多种数据源,提供丰富多样的2D、3D可视化组件,采用拖拽式自由布局,旨在帮助您快速定制和应用属于您自己的数据大屏 大数据应用 推荐系统 推荐系统(Recommender
华为云分布式关系型数据库是什么 华为数据库GaussDB_GaussDB数据库的优点_【免费】_GaussDB分布式数据库_数据库平台 关系数据库管理系统_数据库管理系统、数据库应用 数据库软件免费版 云数据库免费_云数据库免费试用 免费数据库GaussDB NoSQL_云数据库_数据库免费吗
电商大促用什么数据库 电商大促用什么数据库 该方案基于华为云GeminiDB数据库 ,结合数据三副本存储、高性能存储池和数据强一致性等核心技术,为电商行业客户提供高可靠、高性能和低成本的秒杀大促数据库解决方案,解决大促期间海量用户访问造成业务的卡顿、系统崩溃以及数据不一致导致超卖等痛点问题。
大数据学习框架
应用场景
客户痛点:
在软件开发过程中,企业和开发者常面临以下挑战:
- 低效的重复编码:大量时间耗费在样板代码、重复逻辑和基础架构搭建上,影响核心业务逻辑的开发效率。
- 知识壁垒与学习成本:新技术、新框架或遗留系统的理解和应用需要高昂的学习成本,拖慢项目进度。
- 代码质量与维护难题:人工编写的代码可能存在潜在缺陷、性能瓶颈或可读性问题,导致后期维护成本激增。
- 人才短缺与协作摩擦:团队技能差异导致代码风格不统一,新成员上手慢,跨团队协作效率低下。
- 安全与合规 风险:手动编码可能引入安全隐患或违反行业合规要求,增加企业风险。
- 智能编程助手通过AI技术准确解决这些问题,赋能开发者更智能、更高效、更安全地编写代码。
【场景1】代码生成与智能补全
痛点:开发者需反复编写重复性代码(如CRUD接口、数据模型),占用创新时间。
解决方案:通过自然语言描述或上下文理解,自动生成高完整性代码,支持主流语言(Python、Java、Go等),大幅提升编码速度。
【场景2】实时错误检测与修复
痛点:调试耗时占开发周期的30%以上,且复杂错误依赖经验排查。
解决方案:动态分析代码逻辑,即时提示语法错误、类型冲突及潜在缺陷,并提供一键修复建议,降低调试成本。
【场景3】代码优化与重构
痛点:遗留代码性能差、可读性低,重构风险高、周期长。
解决方案:自动识别冗余代码,推荐算法优化方案,安全重构变量、函数及模块结构,保障代码健壮性。
【场景4】文档与测试自动化
痛点:文档缺失或过时,手动编写测试用例覆盖不全。
解决方案:根据代码生成标准化文档(API说明、函数注释),并自动创建单元测试模板,提升覆盖率至60%+。
【场景5】多语言与跨平台开发
痛点:跨技术栈开发需重复学习,适配成本高。
解决方案:智能翻译代码逻辑(如Python转C#),生成多平台兼容代码(Web/iOS/Android),加速全栈开发。
【场景6】安全与合规护航
痛点:手动编码易忽略漏洞(如SQL注入、敏感数据泄露)。
解决方案:深度扫描代码,标记OW AS P Top 10风险,并提供合规性检查(GDPR、HIPAA),降低安全事件概率。
【场景7】团队协作与知识传承
痛点:新成员熟悉代码库需数周时间,协作效率低。
解决方案:通过AI解读代码逻辑,生成可视化流程图,并统一团队编码规范,缩短 onboarding 周。
方案架构
业务架构
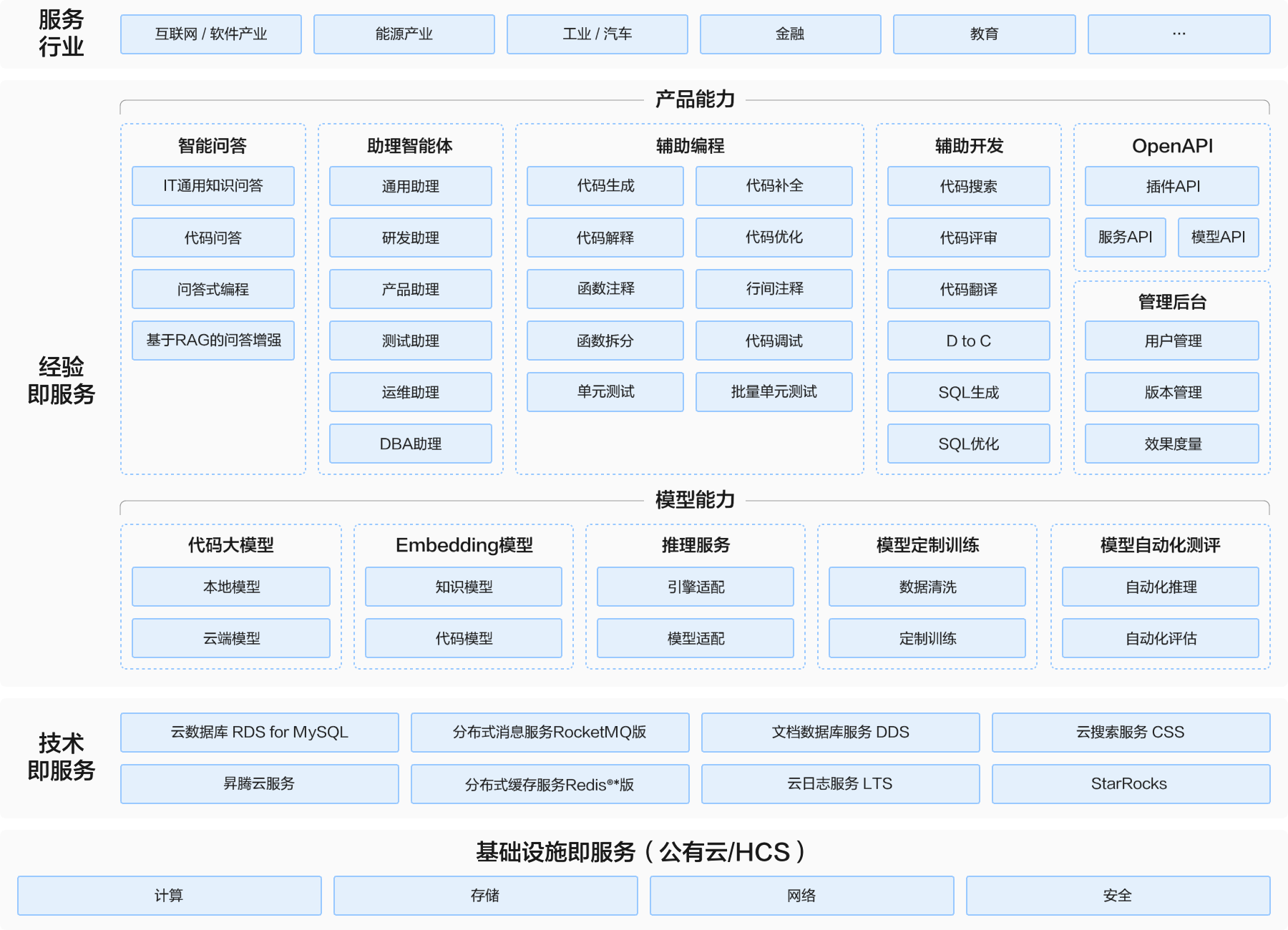
方案主要由华为云昇腾云服务+星火飞码(iFlyCode),基于讯飞星火代码大模型、推理服务、Embedding模型,提供全流程的智能编程助手能力。
- 以IDE插件的产品方式,提供各项产品能力,包括智能问答、助理智能体、辅助编程、辅助开发等。服务于互联网软件行业、能源、工业汽车、金融等各个行业;
- 除了插件的使用方式,也提供OpenAPI的方式,供用户自由灵活的接入使用;
- 效能管理平台,协助客户分析使用情况,包括用户分析、效能度量指标的分析,让使用的结果可度量,可量化。
部署架构图
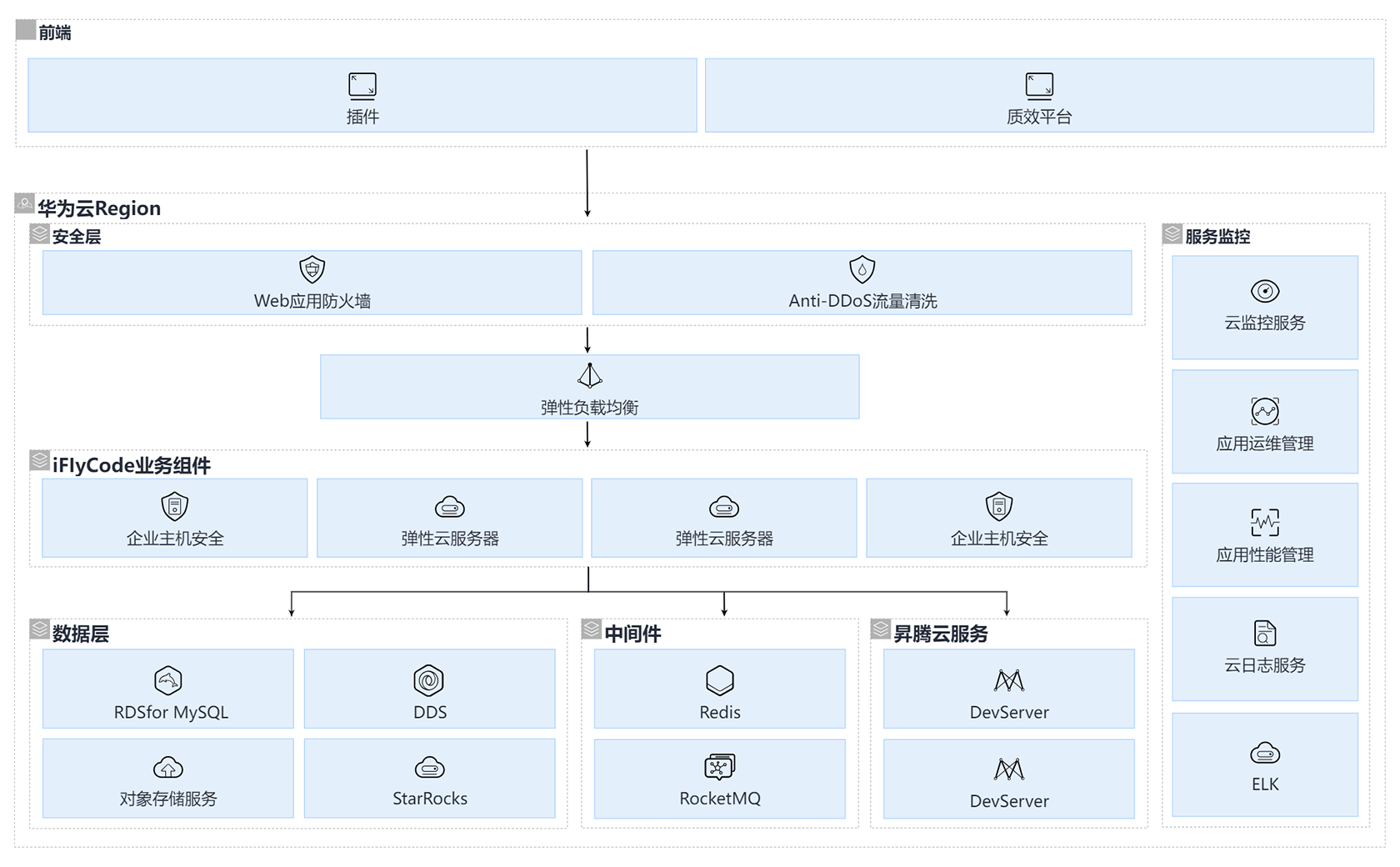
方案通过华为云昇腾云/ DDS /RDS/RocketMQ等实现智能编程助手能力:
- 通过昇腾云服务的算力进行星火大模型推理。
- 通过RDS存储结构化的业务数据。
- 通过DDS存储用户问答数据、使用数据等,然后同步到StarRocks进行报表呈现
- 通过Redis缓存用户登录状态等信息。
- 通过RocketMQ存储业务消息队列。
- 通过StarRocks存储用户使用数据分析结果,用于报表呈现。
方案优势
- 核心效果优异:基于优异的讯飞星火大模型和华为昇腾云服务,经过开源的测试集测评,核心场景能力优先,代码生成采纳率可达52%;
- 独特场景功能:除基础代码辅助功能外,还能提供批量单元测试能力,支持动态修改用例并自动生成测试代码,行覆盖率达80%,人机协同更智能。结合企业代码仓库,智能评审系统可显著提升代码质量与规范性;
- 原生适配自研底座:全国首个自研算力集群训练,在华为AI算力平台的训练效率可达英伟达A100的90%,性能优先;
- 面向客户价值:对于最终客户,通过集成RDS/Redis/DDS/RocketMQ等云服务,替代虚拟机开源组件自建形式,方案整体成本节省3500+元/年。
大数据学习框架常见问题
更多常见问题 >>-
Infima是一个样式框架,专门为内容导向型网站而设计。Infima 与现有 CSS 框架(例如 Bootstrap、Bulma)之间的主要区别在于,它采用现代化的主题化方法(CSS 变量)以及现代化的工具进行构建,并且具有开箱即用的暗模式支持,使其非常适合构建内容导向型网站,例如文档网站。
-
Gatsby 是一个基于 React 的免费、开源框架,可以帮助开发人员构建快速的网站和应用程序。
-
虽然购买学习卡的操作比较简单,但是同学们还是有可能会遇到一些问题。本文让我们来看看一些常见问题的解决方法。
-
VuePress 是基于 Vue 前端开发框架的静态站点生成工具。
-
本文让我们来看看一些优学院关于学习卡的常见问题的解决方法。
-
以当今研究趋势由前馈学习重新转入双向对偶系统为出发点,从解码与编码、识别与重建、归纳与演绎、认知与求解等角度,我们将概括地介绍双向深度学习的历史、发展现状、应用场景,着重介绍双向深度学习理论、算法和应用示例。本课程介绍了双向深度学习理论、算法和应用示例,让你对双向深度学习有初步的认知。
