

AI开发平台MODELARTS-启动推理服务(多模态模型):启动离线推理
 下载AI开发平台MODELARTS用户手册完整版
下载AI开发平台MODELARTS用户手册完整版
启动离线推理
使用如下脚本AscendCloud-LLM/llm_inference/ascend_vllm/vllm-gpu-0.9.0/examples/offline_inference/vision_language.py进行多模态离线推理
- 找到对应系列模型的入口函数,修改模型权重位置,例如qwen2.5-vl,将下图红框修改为模型权重位置:
图1 修改模型权重位置
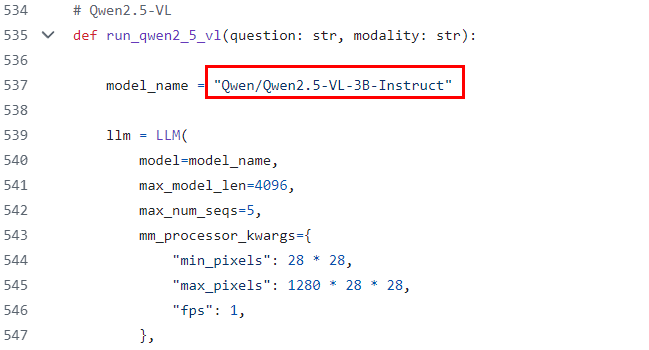
- 修改模型参数,在对应系列模型的入口函数中的LLM中设置参数。
- model:模型地址,模型格式是huggingface的目录格式
- max_num_seqs:最大同时处理的请求数
- max_model_len:推理时最大输入+最大输出tokens数量,输入超过该数量会直接返回
- max_num_batched_tokens:prefill阶段,最多会使用多少token,必须大于或等于--max-model-len,推荐使用4096或8192
- dtype:模型推理的数据类型
- tensor_parallel_size:模型并行数(即使用几卡)
- block_size:PagedAttention的block大小,推荐设置为128
- gpu_memory_utilization:NPU使用的显存比例,复用原vLLM的入参名称,默认为0.9
- trust_remote_code:是否相信远程代码
- distributed_executor_backend="ray":使用ray通信
- 修改模型参数,在SamplingParams中设置参数。
图2 在SamplingParams中设置参数
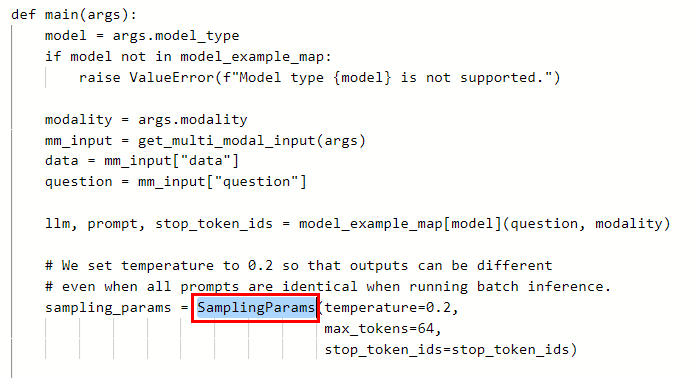
表1 参数说明 参数
是否必选
默认值
参数类型
描述
max_tokens
否
16
Int
每个输出序列要生成的最大tokens数量。
top_k
否
-1
Int
控制要考虑的前几个tokens的数量的整数。设置为-1表示考虑所有tokens。适当降低该值可以减少采样时间。
top_p
否
1.0
Float
控制要考虑的前几个tokens的累积概率的浮点数。必须在 (0, 1] 范围内。设置为1表示考虑所有tokens。
temperature
否
1.0
Float
控制采样的随机性的浮点数。较低的值使模型更加确定性,较高的值使模型更加随机。0表示贪婪采样。
stream
否
False
Bool
是否开启流式推理。默认为False,表示不开启流式推理。
ignore_eos
否
False
Bool
ignore_eos表示是否忽略EOS并且继续生成token。
repetition_penalty
否
1.0
Float
减少重复生成文本的概率。
stop_token_ids
否
None
Int
停止tokens列表。Internvl2.5需要传入,参考离线推理脚本AscendCloud-LLM/llm_inference/ascend_vllm/vllm-gpu-0.9.0/examples/offline_inference/vision_language.py的stop_token_ids。
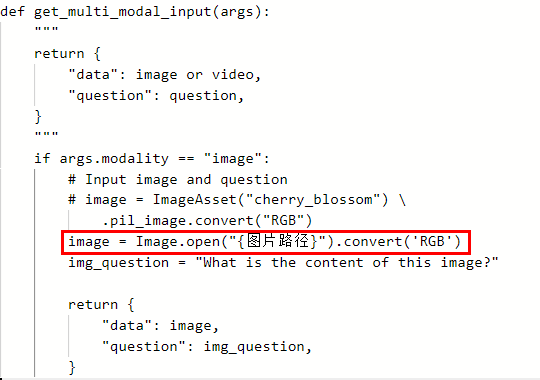
- 指定图片路径。指定本地图片路径需在文件开头增加代码from PIL import Image,在get_multi_modal_input函数中新增如下代码image = Image.open("{图片路径}").convert('RGB')。
图3 指定图片路径
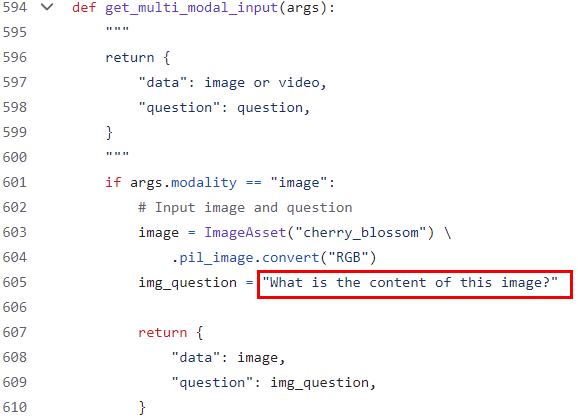
- 指定输入文本。
图4 指定输入文本
- 启动推理脚本
python vision_language.py --model-type qwen2_5_vl
脚本运行参数说明:
--model-type:模型类型,目前可选参数为internvl_chat、qwen2_5_vl。
--num-prompts:单次运行输入的prompt的数量,默认为4。
--modality:输入类型,目前可选参数为image、video,默认为image。
--num-frames:从视频中提取的帧数,默认为16。

