

AI开发平台MODELARTS-优化算子执行:加速慢算子的执行速度
时间:2024-04-30 18:09:29
 下载AI开发平台MODELARTS用户手册完整版
下载AI开发平台MODELARTS用户手册完整版
复制链接到剪贴板
分享文章到微博
分享文章到朋友圈
加速慢算子的执行速度
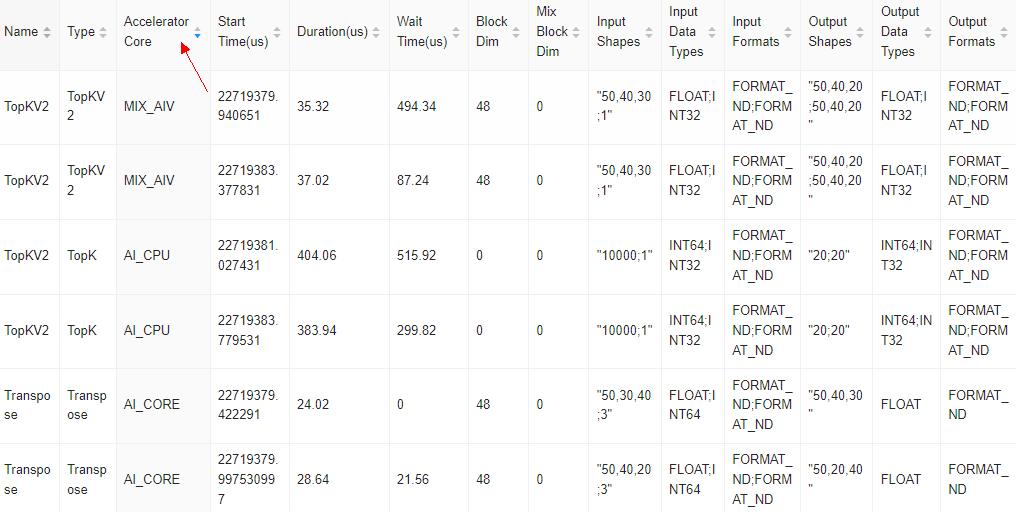
首先需要寻找执行速度比较慢的NPU算子列表,Kernel视图包含在NPU上执行的所有算子的信息,主要用于确认高耗时算子。
图7 Kernel视图
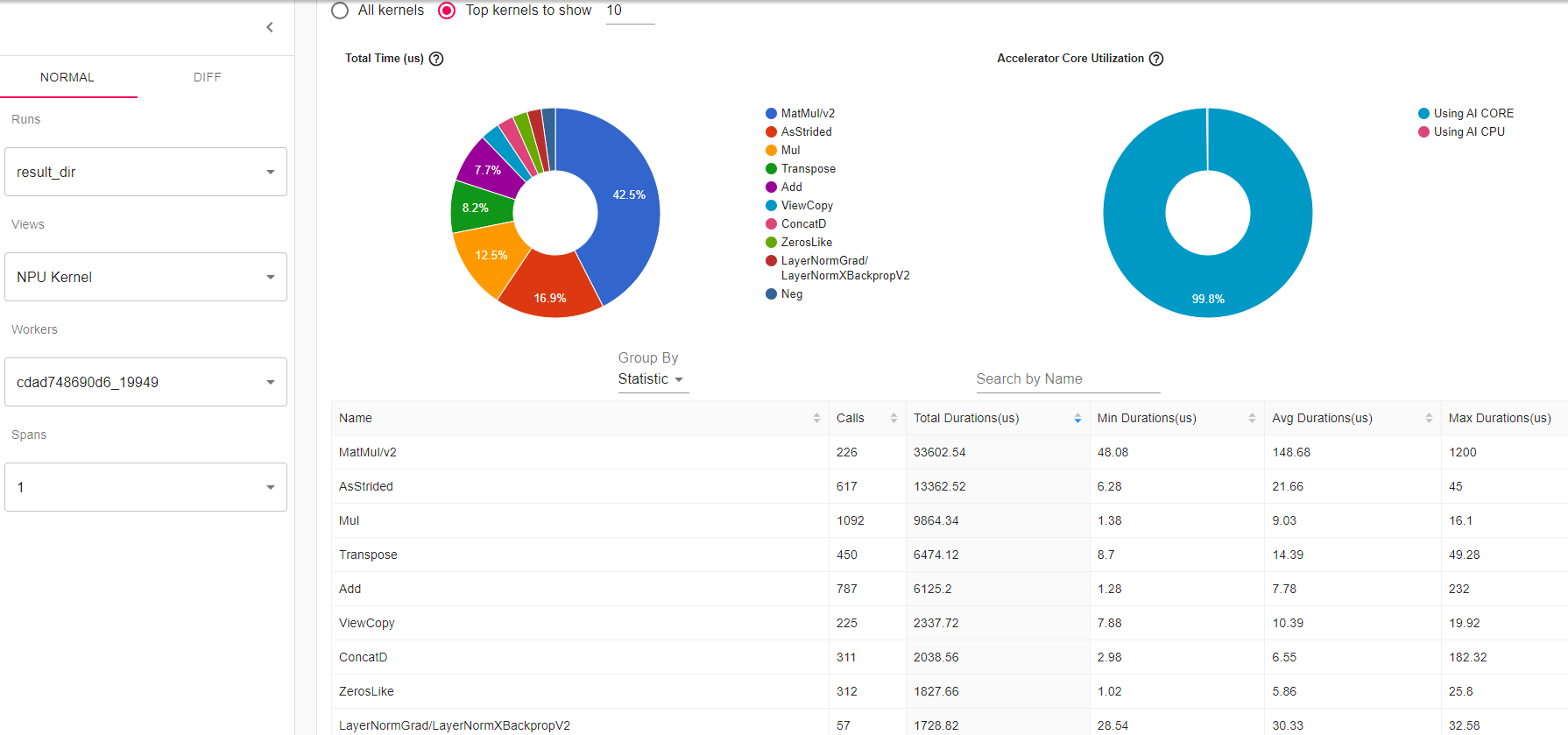
推荐基于以下思路尝试优化:
- 搜索Cast类算子,查看是否Cast类算子最大耗时超过30us或者总耗时占比超过1%,如果超过,需尝试启动混合精度训练,详见此处。
图8 Cast类算子
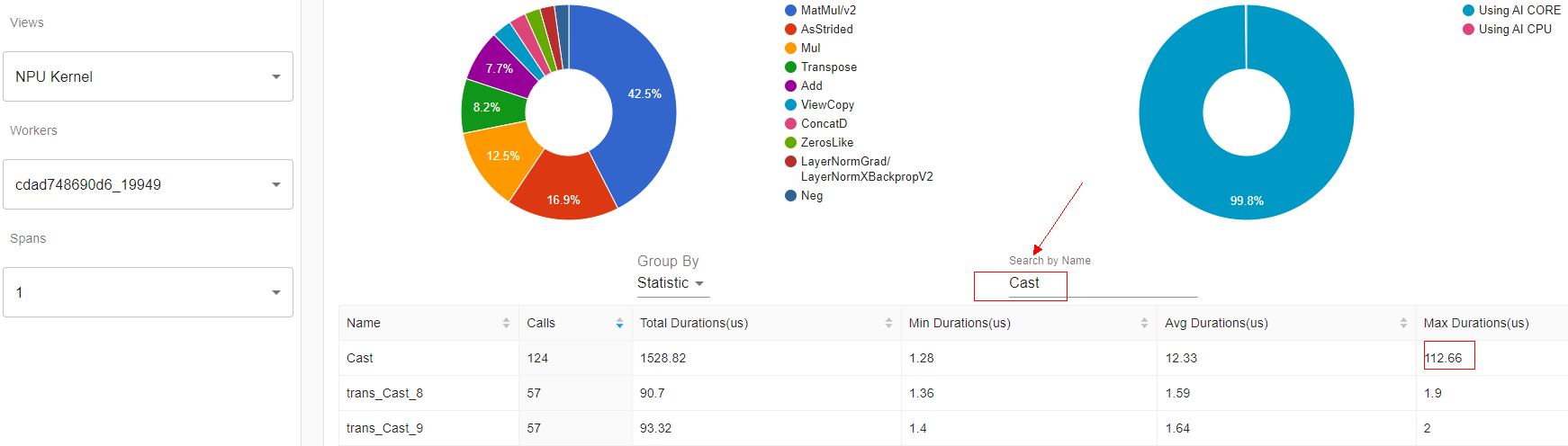
- 基于Accelerator Core排序,统计AI_CPU算子,如果有AI_CPU类算子执行时长超过1000us或者AI_CPU类算子总执行时长占比超过10%,可尝试修改代码替换API_CPU算子。
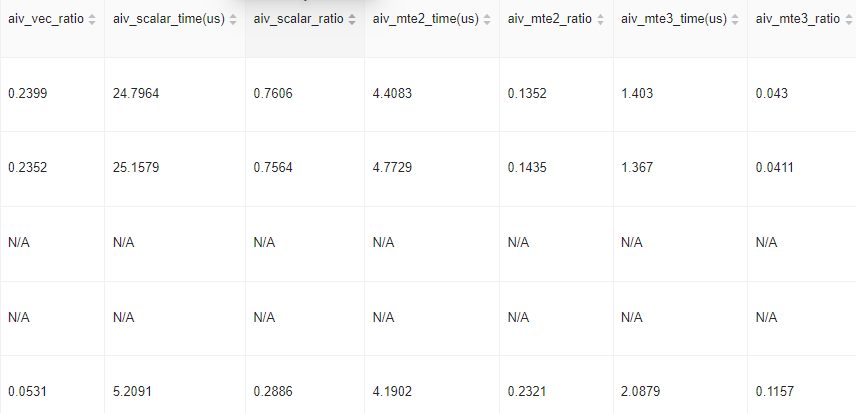
- 如果遇到算子运行期间NPU的计算单元和存储单元使用率都未达到80%(查看aiv_*_ratio和aic_*_ratio是否达到0.8),或者算子的“Block Dim”小于AI Core/Vector Core,可尝试使用AOE算子调优,提高NPU硬件资源利用率。
图10 aiv_*_ratio
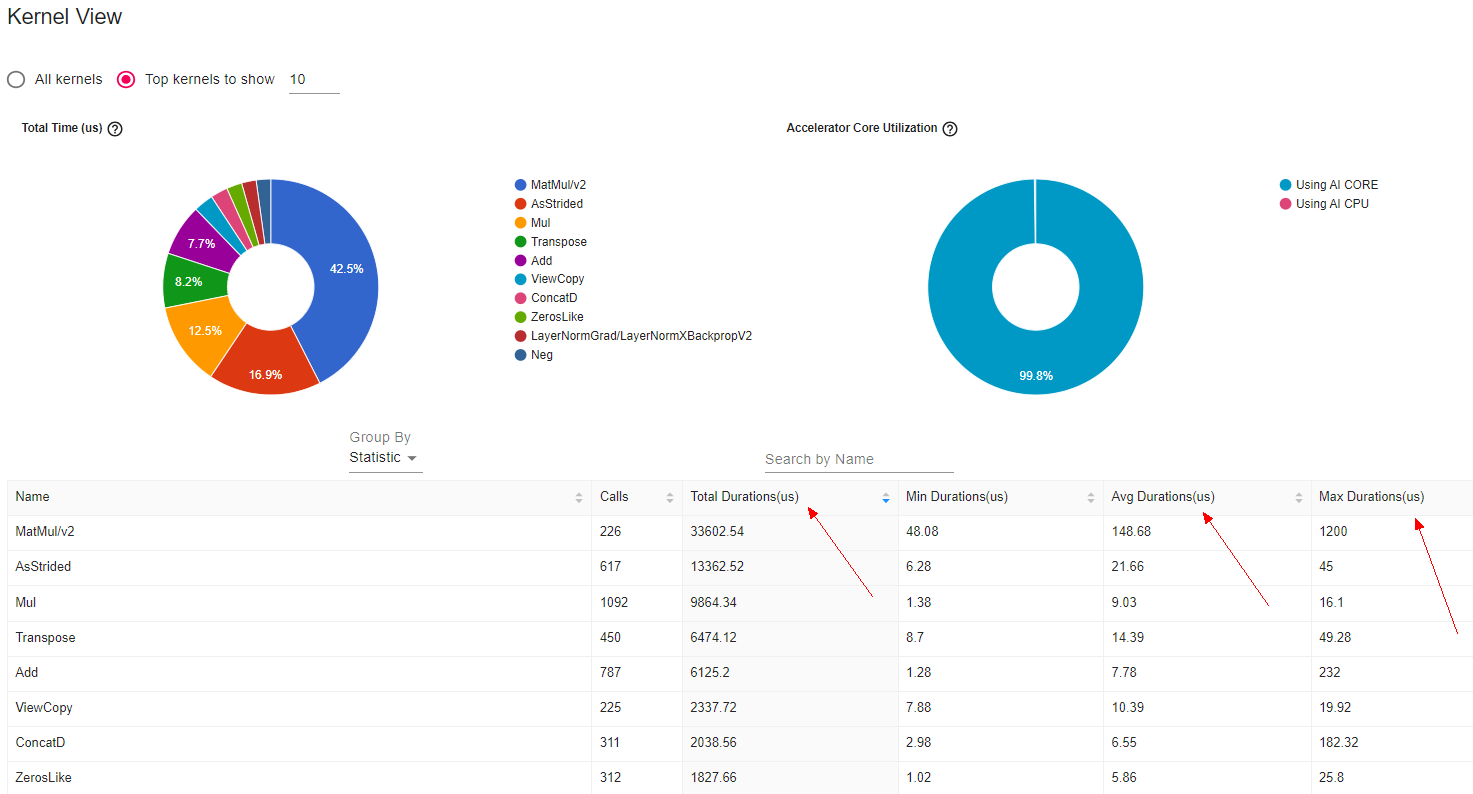
- 针对总耗时最长、平均执行耗时最长以及最大耗时的三种排序的TOP算子,可联系华为工程师获得帮助。
图11 耗时排序
support.huaweicloud.com/bestpractice-modelarts/modelarts_10_2510.html
看了此文的人还看了
CDN加速
GaussDB
文字转换成语音
免费的服务器
如何创建网站
域名网站购买
私有云桌面
云主机哪个好
域名怎么备案
手机云电脑
SSL证书申请
云点播服务器
免费OCR是什么
电脑云桌面
域名备案怎么弄
语音转文字
文字图片识别
云桌面是什么
网址安全检测
网站建设搭建
国外CDN加速
SSL免费证书申请
短信批量发送
图片OCR识别
云数据库MySQL
个人域名购买
录音转文字
扫描图片识别文字
OCR图片识别
行驶证识别
虚拟电话号码
电话呼叫中心软件
怎么制作一个网站
Email注册网站
华为VNC
图像文字识别
企业网站制作
个人网站搭建
华为云计算
免费租用云托管
云桌面云服务器
ocr文字识别免费版
HTTPS证书申请
图片文字识别转换
国外域名注册商
使用免费虚拟主机
云电脑主机多少钱
鲲鹏云手机
短信验证码平台
OCR图片文字识别
SSL证书是什么
申请企业邮箱步骤
免费的企业用邮箱
云免流搭建教程
域名价格


推荐文章
